

Escuela de Ciencia y Tecnología, home
El grupo de investigadores de la Escuela de Ciencia y Tecnología liderado por Ezequiel Álvarez fue reconocido como socio de confianza (“trusted partner”) de arXiv, el sitio de internet creado en 1991 que revolucionó la forma de comunicar avances científicos. El reconocimiento fue alcanzado por el desarrollo de un servicio que recomienda la lectura de artículos científicos a partir de un algoritmo que aprende de lo que cada usuario lee.
El trabajo de lxs investigadores es producir conocimiento sobre el mundo. Compartir ese conocimiento es clave para el progreso de la ciencia: permite que el conocimiento producido por una persona, pueda ser usado por otras para hacer nuevos descubrimientos y beneficiar a la sociedad. La primera gran innovación para difundir ciencia se produjo en 1665 con la creación de la revista “Philosophical Transactions” que estableció los conceptos de prioridad de publicación y revisión por pares. Este modelo de publicación se convirtió en el estándar y se utiliza actualmente en más de 30.000 revistas, pero tiene la desventaja de restringir el acceso de publicación y de lectura, mediante el arancelamiento, y de ralentizar un año aproximadamente la difusión de cada hallazgo, además de dejar afuera a los resultados negativos.
La alternativa al modelo de publicaciones científicas con revisión de pares llegó en 1991, con el servidor público de artículos pre-prints arXiv.org creado por el biólogo Paul Ginsparg. Se trata de uno de los primeros sitios de Internet y de un parte aguas en la historia de la ciencia. Este innovador modelo permite el acceso a publicaciones científicas de manera digital y gratuita, antes de que sean revisadas por pares. El proceso de publicación de artículos lleva apenas unos días y revolucionó la comunicación científica, primero entre físicxs y después en el resto de las disciplinas, a partir de nuevos servidores inspirados en arXiv, como reconstruyó YuoReka Science en este video (clic aquí).
Actualmente arXiv publica más de 100.000 artículos preprints por año. Y otros tanto son publicados en otros servidores. Para entender cómo este modelo de comunicación de la ciencia está acelerando el avance científico se recomienda la lectura de esta nota de Gaspar Grieco (clic aquí).
Desde el punto de vista científico esta abundancia de información representa un desafío. ¿Qué artículos leer primero? Aquí es donde entra en juego el aporte de un grupo de investigadores del International Center for Advanced Studies (ICAS) de la Escuela de Ciencia y Tecnología (ECyT) de la UNSAM.
El grupo liderado por el investigador Ezequiel Álvarez desarrolló una aplicación basada en inteligencia artificial que jerarquiza la importancia de los artículos científicos no leídos a partir de las prácticas de lectura de cada usuario. Se trata de IArxiv.org, una herramienta también de acceso libre y gratuito que impactó de lleno en los países que más ciencia producen y que la semana pasada fue incorporada formalmente al sitio Arxiv, tal como se anunció en su blog (clic aquí).
El servicio —que ya está disponible para los campos de la física de altas energías, la cosmología, la gravitación y la astrofísica— facilita la consulta de artículos científicos diariamente. La comunidad científica global reconoció sus beneficios y ya registró más de 1.500 usuarios.
El desarrollo del algortimo con inteligencia artificial fue publicado en febrero de 2020 en arXiv (clic aquí), pero además fue llevado a la práctica mediante la creación de una aplicación. Álvarez lo contó así: “Desarrollamos el algoritmo y lo compartimos mediante una publicación, pero además creamos una aplicación para que fuera utilizada. Ahora la noticia es que esa aplicación fue incorporada formalmente por arXiv. Es uno de los sitios de Internet más importantes. Para nosotros es un reconocimiento y un privilegio ser reconocidos como ‘trusted partners’”, aseguró Álvarez.
“El pasaje del algoritmo al servicio es todo un desafío, porque implica gestionar el funcionamiento diario de un servicio: que funcionen los botones cada vez que colegas de todo el mundo quieren recibir recomendaciones. Además, estamos expandiendo el servicio a nuevos campos. Por ahora funciona para física, pero estamos trabajando en un upgrade hecho a medida para científicos para los próximos meses”, agregó Álvarez.
Cómo funciona el algoritmo de recomendaciones IarXiv
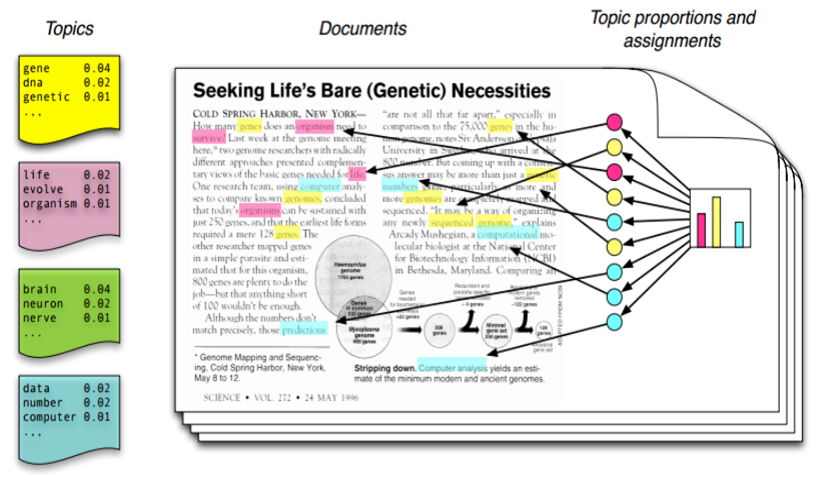
El algoritmo elegido para obtener esa herramienta fue el Latent Dirichlet Allocation (LDA), un método de aprendizaje artificial no supervisado que mina los textos para encontrar la relación entre palabras y su frecuencia de aparición en otros documentos.
“A partir de esas observaciones y utilizando el Teorema de Bayes de la estadística, IArxiv reconstruye los tópicos que forman los documentos. Esto permite convertir cualquier documento en un vector de búsqueda”, explicó Álvarez en esta nota (clic aquí). “Cada usuario tiene un vector que se construye a partir de los artículos propios y de los que lee. Con ese vector, el sistema calcula una ‘distancia’ entre el usuario y cualquier otro artículo, lo que le permite ordenar los contenidos por su importancia relativa”, completó el investigador.
algortimo, Alvarez, Artículos, arXiv, avance científico, ciencia, ECyT, IarXiv, inteligencia artificial, machine learning, papers, pre-prints, preprints, producción científicas, recomendaciones de lectura, revolución, UNSAM
 WEB UNSAM
WEB UNSAM

