#TalentoUNSAM, Escuela de Ciencia y Tecnología, home
Investigadores de la Escuela de Ciencia y Tecnología de la UNSAM desarrollaron una aplicación basada en inteligencia artificial que organiza bibliografía científica según las preferencias de cada usuarix. La herramienta, que se presentó a la comunidad científica internacional el 10 de febrero, ya tiene más de 600 usuarixs registrados.
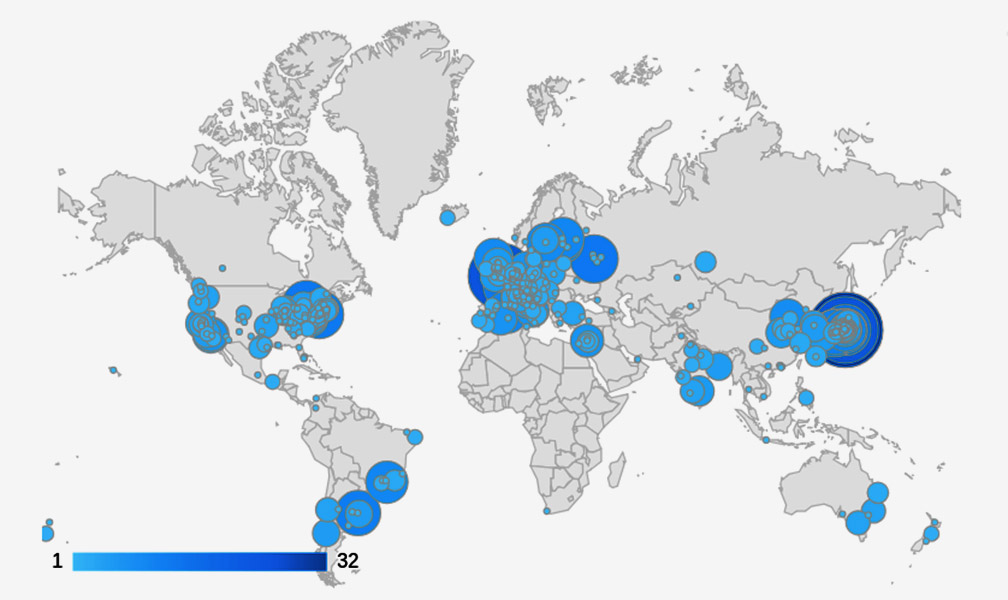
Investigadores del International Center for Advanced Studies (ICAS) de la Escuela de Ciencia y Tecnología (ECyT) de la UNSAM desarrollaron una aplicación basada en inteligencia artificial que aprende las preferencias temáticas de cada usuarix y ordena artículos científicos por orden de importancia. Se trata de IArxiv.org, una herramienta de acceso libre y gratuito que, a nueve días de su lanzamiento, impactó de lleno en los países que más ciencia producen.
La nueva aplicación —que, por el momento, solo está disponible para los campos de la física de altas energías, la cosmología, la gravitación y la astrofísica— facilita la consulta de artículos científicos a diario. La comunidad científica global reconoció sus beneficios y ya registró más de 600 usuarios.
“Descubrimos que teníamos la posibilidad de crear esta herramienta a fines de 2019. Desde entonces, no paramos”, cuenta Ezequiel Álvarez, investigador del ICAS y uno de los creadores de IArxiv. “Fue una carrera sin descanso. Sabíamos que otros dos grupos de Estados Unidos y Europa estaban en la misma línea de investigación, pero nosotros terminamos primero. Pudimos presentar la plataforma el 10 de febrero de 2020, lo que fue un alivio y una satisfacción”, celebra el físico.
El equipo que desarrolló la plataforma se completa con Daniel de Florian, director del ICAS y del Centro de Inteligencia Artificial Interdisciplinaria (IAI) de la UNSAM; Federico Lamagna, investigador del Centro Atómico Bariloche; Manuel Szewc, investigador del ICAS; y César Miquel, fundador de la empresa Easytech.
“Veníamos discutiendo sobre métodos de machine learning para el procesamiento de lenguaje natural desde hacía meses”, cuenta de Florian. “Nos interesaba aprovechar esa función para crear una herramienta que facilitara una de las principales tareas de los científicos, que es la de mantenerse actualizados en sus respectivos campos de estudio”.
El algoritmo elegido para obtener esa herramienta fue el Latent Dirichlet Allocation (LDA), un método de aprendizaje artificial no supervisado que mina los textos para encontrar la relación entre palabras y su frecuencia de aparición en otros documentos.
“A partir de esas observaciones y utilizando el Teorema de Bayes de la estadística, IArxiv reconstruye los tópicos que forman los documentos. Esto permite convertir cualquier documento en un vector de búsqueda”, explica Álvarez. “Cada usuario tiene un vector que se construye a partir de los artículos propios y de los que lee. Con ese vector, el sistema calcula una ‘distancia’ entre el usuario y cualquier otro artículo, lo que le permite ordenar los contenidos por su importancia relativa”, completa el investigador.
A futuro, el plan es expandir la herramienta a otras ramas de la ciencia incorporándole funciones de búsqueda bibliográfica basadas en LDA y machine learning. “La comunidad científica no es infinita. De todos modos, con el tiempo y la incorporación de nuevas funciones, el número de usuarios va a seguir creciendo. Ahora los científicos tienen que testear el servicio”, dice Álvarez.
 WEB UNSAM
WEB UNSAM